
We are very excited to release Findkit Workers to a beta which is immediately available to all organizations with at least one paid subscription and for free plan users on request, please contact us!
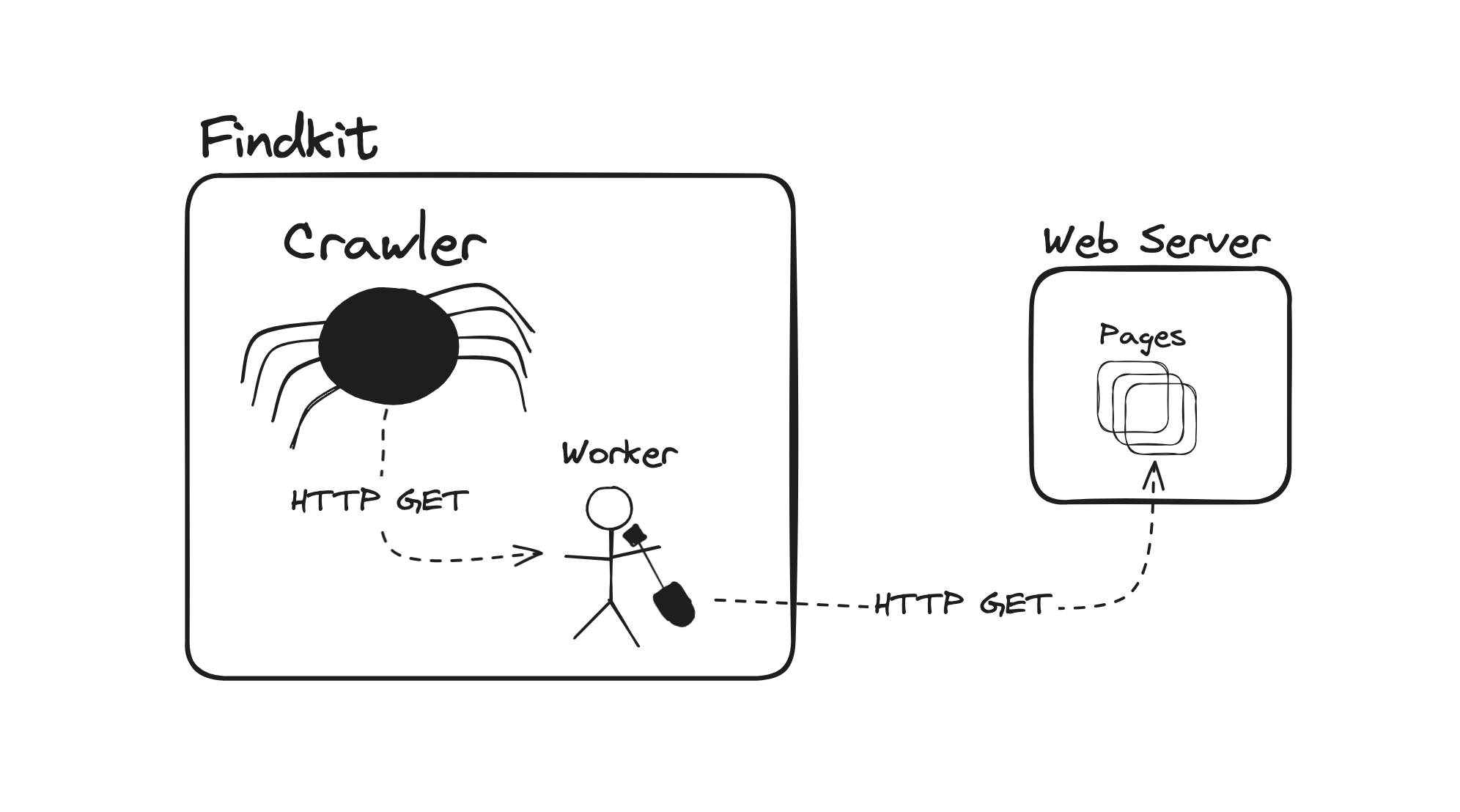
So what are the Findkit Workers? They are like Cloudflare Workers but for website crawlers. Cloudflare Workers allows developers to execute custom Javascript code when a HTTP Request comes in. Findkit Workers work in reverse: When the crawler is about to send a HTTP Request developer can modify/intercept that request using the Fetch API:
export default {
async fetch(request) {
// Add basic auth header
request.headers.set("Authorization", "Authorization: Basic Ym9iOmh1bnRlcjI=");
const response = await fetch(request);
return response;
}
}
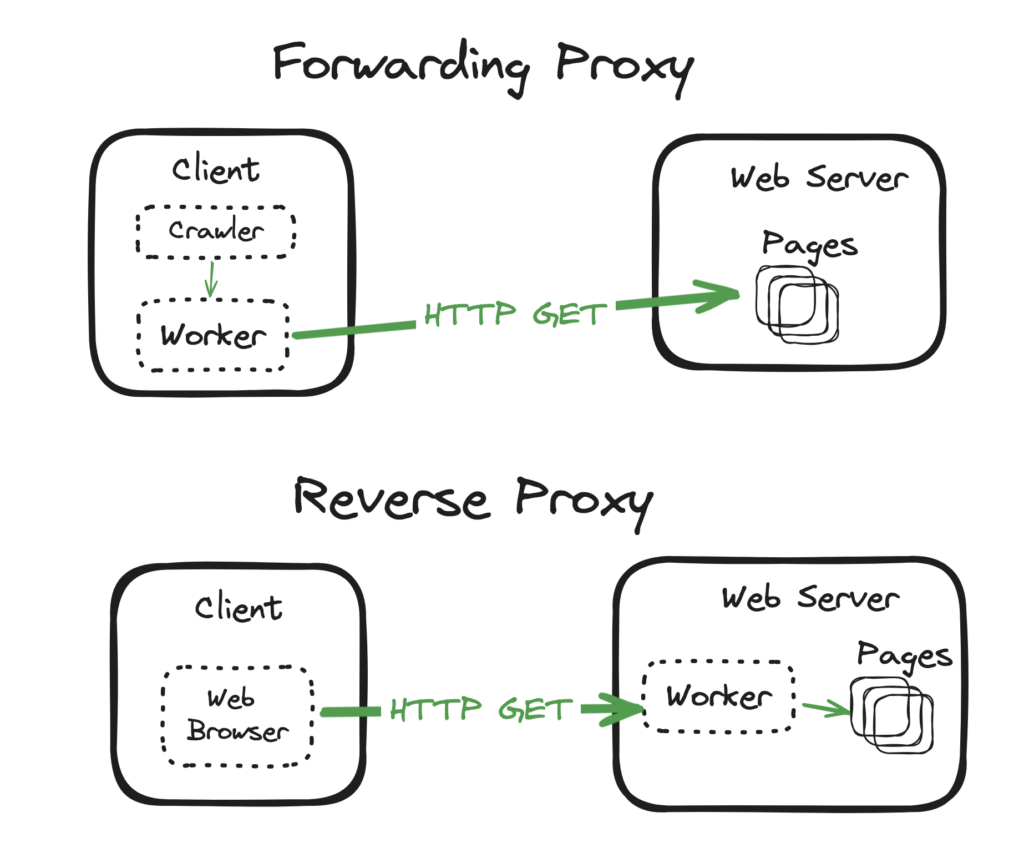
In other words Findkit Workers act like a Forwarding Proxy where as Cloudflare Workers is a Reverse Proxy.
The request and response can be modified in any way. It is also possible to create new ones with new Request() and new Response(). You may even return a generated response directly which will bypass sending the request completely.
DOM Access
In addition to request / response manipulation Findkit Workers gives you access to a DOM Document generated from the page HTML which can be used to customize what goes into the Findkit Search Index. For example you can use it to scrape HTML elements into the Findkit Custom Fields:
export default {
async html(page, context, next) {
// The page.window property is like the window
// object in a web browser but instead of being global
// it is just a local variable
const document = page.window.document;
const result = await next(page);
// Modify the result by adding a custom field
const price = document.querySelector(".price")?.innerText;
result.customFields.price = {
type: "number",
value: Number(price),
};
return result;
},
};
This is extremely powerful when you need work with websites you don’t have full control over. It is also very easy to learn because it uses the same API as web browsers, which is familiar to all web developers.
Use Cases
The use cases for Findkit Workers are practically unlimited but here’s some use cases to get the idea of
- Add authentication headers to crawl sites behind a login screen
- Use the
fetch()function with an external service to make crawler notifcations - Split a single web page to multiple search results with Fragment Pages
- Parse weird file formats using 3rd party services
- Dynamically add tags and custom fields based on the page content
- Prevent the crawler from making certain requests
- Send the page content to an another service. For example update AI Model with the website content
- Collect data into a custom format for exporting
- Skip content indexing and just use the workers to keep site content in sync with another system using the scheduled and live crawling
- Generate or modify sitemaps and robot.txt files on the fly
- Add or modify crawler data-attributes on the fly
If you have any questions or wonder if your use case can be implemented using Findkit Workers please contact us!
Hop on to the Workers documentation to learn more: